
こんにちは!じゃいごテックのあつしです。
今回はpaiza Cランクレベルアップメニュー から辞書という問題を解説します。
この問題集は連想配列の使い方に関する3個のSTEP問題(C級)とFINAL問題(C級)で構成されていて、STEP問題を解いて行けばFINAL問題も解けるはず!となっています。
Rubyではハッシュが連想配列に該当します。配列の様に複数のデータを格納でき、インデックスではなく、キーと呼ばれる文字列やシンボルで値にアクセスします。
STEP問題を解いてみる
STEP問題はハッシュの基本操作の問題です。
Cランク問題となっており、配列で解こうとすると確かに難しいかもしれません。
今回は連想配列がテーマとなっていますので、ハッシュを使って解いていきます。
STEP1: 辞書の基本 (paizaランク C 相当)
STEP1 はハッシュオブジェクトを生成し、指定されたキーの値を出力する問題です。
入力例
<<EOS 入力例1 2 Kirishima 1 Kyoko 2 Kirishima 出力例1 1 入力例2 3 paiiza 2 paiza 1 paiiiza 3 paiiiza 出力例2 3 EOS
解答例
n = gets.to_i
hash = {}
n.times do
key, val = gets.split
hash[key] = val.to_i
end
puts hash[gets.chomp]
STEP2: 辞書のデータ更新 (paizaランク C 相当)
STEP2 ハッシュの値を更新していき、指定されたキーの値を出力する問題です。
入力例
<<EOS 入力例1 2 Kirishima Kyoko 2 Kyoko 1 Kyoko 2 Kyoko 出力例1 3 入力例2 3 paiiza paiza paiiiza 2 paiiza 2 paiiiza 3 paiza 出力例2 0 EOS
解答例
n = gets.to_i
hash = {}
n.times do
hash[gets.chomp] = 0
end
m = gets.to_i
m.times do
key, val = gets.split
hash[key] += val.to_i
end
puts hash[gets.chomp]
STEP3: 辞書式ソート (paizaランク D 相当)
STEP3 はハッシュの値を更新していき、最後にキーでソートして出力する問題です。
入力例
<<EOS 入力例1 2 MIDORIKAWA KIRISHIMA 2 KIRISHIMA 1 KIRISHIMA 2 出力例1 3 0 入力例2 3 PAIIZA PAIZA PAIIIZA 2 PAIIZA 2 PAIIIZA 3 出力例2 3 2 0 EOS
解答例
n = gets.to_i
hash = {}
n.times do
hash[gets.chomp] = 0
end
m = gets.to_i
m.times do
key, val = gets.split
hash[key] += val.to_i
end
sorted_hash = hash.sort.to_h
puts sorted_hash.values
辞書 (paizaランク C 相当) を解いてみる
※ paiza Cランクレベルアップメニューより
問題
p 人のグループ A , q 人のグループ B , r 人のグループ C があります。各グループのメンバーにはそれぞれ番号がつけられており、 A グループの i 番目の人は B グループの j 番目の人に仕事を任せ、 B グループの j 番目の人は与えられた仕事を C グループの k 番目の人に任せます。すると結局、 A グループの i 番目の人の仕事をするのは C グループの k 番目の人だということになります。
パイザ君は A グループの各人の仕事を結局 C グループの誰が行うことになるのか知りたがっています。 A グループの人のそれぞれが最終的に C グループの誰に仕事を頼むことになるのかを、 A グループの人の番号が小さい順に p 行出力してください。
入力される値
入力は以下のフォーマットで与えられます。
p q r i_1 j_1 ... i_p j_p j'_1 k_1 ... j'_q k_q
1 行目には A グループ、 B グループ、 C グループのそれぞれの人数 p , q , r が半角スペース区切りで与えられます。
2 行目から (p + 1) 行目までは A グループの人の番号とその人が仕事を頼む B グループの人の番号 i_a, j_a (1 ≤ a ≤ p) が半角スペース区切りで、 (p + 2) 行目から (p + q + 2) 行目までは B グループの人の番号とその人が仕事を頼む C グループの人の番号 j’_b , k_b (1 ≤ b ≤ q) が半角スペース区切りで与えられます。
入力値最終行の末尾に改行が1つ入ります。
期待する出力
A グループの i_c 番目の人が C グループの k_c 番目の人に仕事を頼むとしたとき (1 ≤ c ≤ p) 、各 i_c, k_c をそれぞれ半角スペース区切りで、 i_c が小さい順に p 行出力してください。
末尾に改行を入れ、余計な文字、空行を含んではいけません。
条件
すべてのテストケースにおいて、以下の条件をみたします。
- 1 ≤ p , q , r ≤ 50
- 1 ≤ i_a ≤ p , 1 ≤ j_a , j'_b ≤ q , 1 ≤ k_b ≤ r (1 ≤ a ≤ p , 1 ≤ b ≤ q)
- 各 i_a は全て異なる
- 各 j'_b は全て異なる
A グループから仕事を頼まれた B グループの人は必ずその仕事を C グループの誰かに頼みます。 B グループに関する入力には「余計な」ものも含まれます。すなわち、 A グループの誰からも仕事を頼まれていない B グループの人に関して、その人が C グループの誰に仕事を頼むかについての情報が与えられることもあります。
攻略ポイント
ポイント
問題を解く流れ
問題が少しややこしいので、まずは情報を整理しましょう。
こういう問題が出たときは、入力例・出力例を紙に書いてみると理解しやすくなると思います。
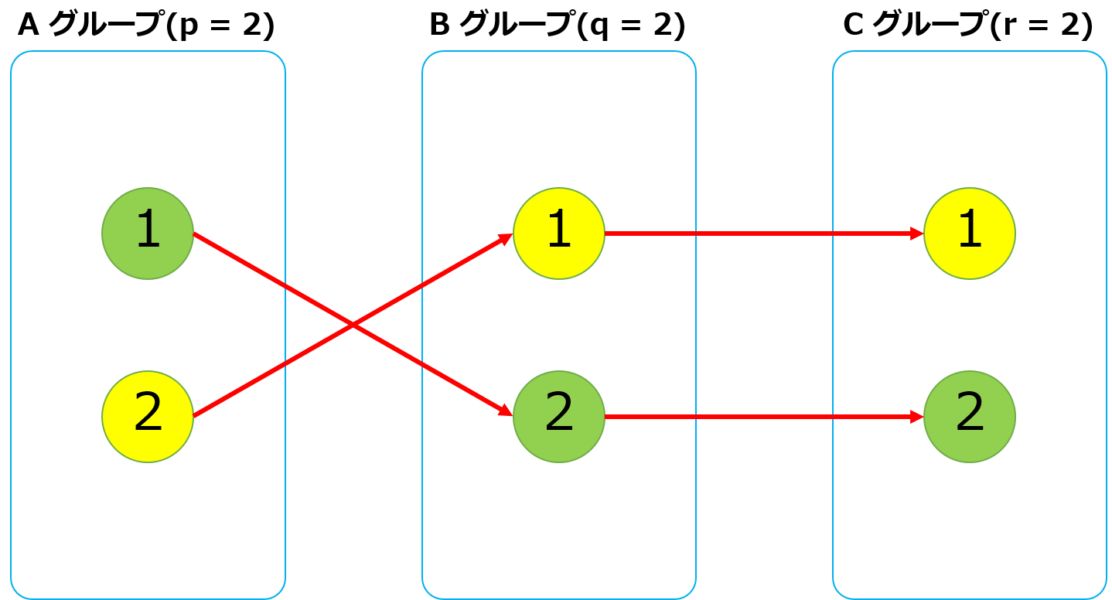
入力例1
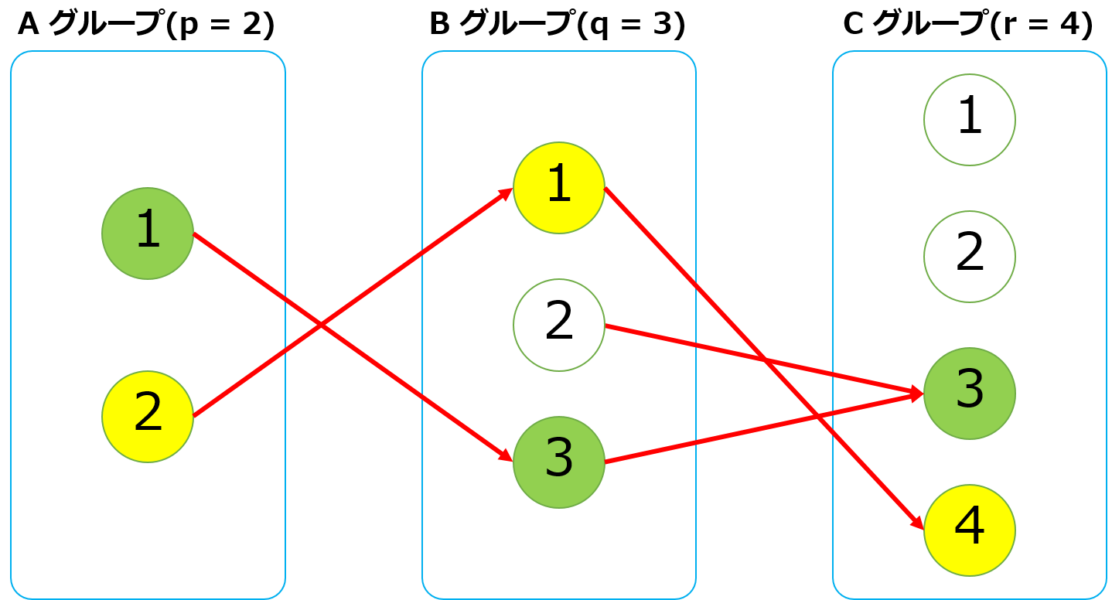
入力例2
- AグループからCグループへの繋がりを調べる。
- 入力情報は番号順ではないのでAグループの番号順でソートする必要がある。
やりたいことが明確になりましたので、解いていきます。
入出力例をコピペしてヒアドキュメントで変数に代入し、データを確認します。正しく受け取れていれば確認用コードは削除します。
INPUT1 = <<~"EOS" 2 2 2 2 1 1 2 1 1 2 2 EOS OUTPUT1 = <<~"EOS" 1 2 2 1 EOS INPUT2 = <<~"EOS" 2 3 4 1 3 2 1 2 3 3 3 1 4 EOS OUTPUT2 = <<~"EOS" 1 3 2 4 EOS # 確認用コード p INPUT1 # > "2 2 2\n2 1\n1 2\n1 1\n2 2\n" p INPUT2 # > "2 3 4\n1 3\n2 1\n2 3\n3 3\n1 4\n"
続いて問題を解くメソッド( solve メソッドとします)を変数の下に定義します。
まず、入力データを受け取る処理を書きます。
入力された文字列を改行で分割し、1行目で整数p, q, rを取得、続くp行の半角スペース区切りの整数のペア(AグループからBグループに依頼する情報)をハッシュa_to_b に格納し、続くq行の半角スペース区切りの整数のペア(BグループからCグループに依頼する情報)をハッシュb_to_cに格納します。
def solve(input_lines)
# 標準入力の受け取り
input_lines = input_lines.split("\n")
p, q, r = input_lines.shift.split.map(&:to_i)
a_to_b = {}
input_lines.shift(p).each do |line|
key, val = line.split.map(&:to_i)
a_to_b[key] = val
end
b_to_c = {}
input_lines.shift(q).each do |line|
key, val = line.split.map(&:to_i)
b_to_c[key] = val
end
# 確認用コード
[p, q, r, a_to_b, b_to_c]
end
# 確認用コード
p solve(INPUT1)
# > [2, 2, 2, {2=>1, 1=>2}, {1=>1, 2=>2}]
p solve(INPUT2)
# > [2, 3, 4, {1=>3, 2=>1}, {2=>3, 3=>3, 1=>4}]
整数p, q, rとハッシュa_to_b, b_to_cのデータが正しく受け取れていれば、solve メソッドにAグループとCグループの繋がりを調べる処理を追加していきます。
a_to_bの値をキーに持つb_to_cの値はAグループメンバーからの仕事を受けるCグループのメンバーとなります。
def solve(input_lines)
# 標準入力の受け取り
input_lines = input_lines.split("\n")
p, q, r = input_lines.shift.split.map(&:to_i)
a_to_b = {}
input_lines.shift(p).each do |line|
key, val = line.split.map(&:to_i)
a_to_b[key] = val
end
b_to_c = {}
input_lines.shift(q).each do |line|
key, val = line.split.map(&:to_i)
b_to_c[key] = val
end
# AグループとCグループの繋がりを調べる
a_to_c = {}
a_to_b.each do |key, val|
# a_to_b の値が b_to_c のキーとなる
a_to_c[key] = b_to_c[val]
end
# a_to_c をAグループの番号順でソートする([key, val] の配列)
sorted_ary = a_to_c.sort
# 確認用コード
sorted_ary
end
# 確認用コード
p solve(INPUT1)
# > [[1, 2], [2, 1]]
p solve(INPUT1) == OUTPUT1
# > false
p solve(INPUT2)
# > [[1, 3], [2, 4]]
p solve(INPUT2) == OUTPUT2
# > false
あとは出力形式を整えれば完成です。
p solve(INPUT1) を puts solve(STDIN.read) に変更すれば正解となりますが、p solve(INPUT1) == OUTPUT1 -> true を確認するために、結果を改行区切りの文字列に変換して、末尾にも改行を加えます。
def solve(input_lines)
# 標準入力の受け取り
input_lines = input_lines.split("\n")
p, q, r = input_lines.shift.split.map(&:to_i)
a_to_b = {}
input_lines.shift(p).each do |line|
key, val = line.split.map(&:to_i)
a_to_b[key] = val
end
b_to_c = {}
input_lines.shift(q).each do |line|
key, val = line.split.map(&:to_i)
b_to_c[key] = val
end
# AグループとCグループの繋がりを調べる
a_to_c = {}
a_to_b.each do |key, val|
# a_to_b の値が b_to_c のキーとなる
a_to_c[key] = b_to_c[val]
end
# a_to_c をAグループの番号順でソートする([key, val] の配列になる)
sorted_ary = a_to_c.sort
# 行を改行で連結、行の要素を半角スペースで連結にして末尾に改行を追加
sorted_ary.map { |item| item.join(" ") }.join("\n") << "\n"
end
# 確認用コード
p solve(INPUT1)
# > "1 2\n2 1\n"
p solve(INPUT1) == OUTPUT1
# > true
p solve(INPUT2)
# > "1 3\n2 4\n"
p solve(INPUT2) == OUTPUT2
# > true
確認用コードを標準入力からのデータ受け取りに変更して、動作確認をしたら提出します。
複数行のデータ受け取りなので STDIN.read を使います。(入力終了は Ctrl+D 又は Ctrl+Z)
解答コード
def solve(input_lines)
# 標準入力の受け取り
input_lines = input_lines.split("\n")
p, q, r = input_lines.shift.split.map(&:to_i)
a_to_b = {}
input_lines.shift(p).each do |line|
key, val = line.split.map(&:to_i)
a_to_b[key] = val
end
b_to_c = {}
input_lines.shift(q).each do |line|
key, val = line.split.map(&:to_i)
b_to_c[key] = val
end
# AグループとCグループの繋がりを調べる
a_to_c = {}
a_to_b.each do |key, val|
# a_to_b の値が b_to_c のキーとなる
a_to_c[key] = b_to_c[val]
end
# a_to_c をAグループの番号順でソートする([key, val] の配列になる)
sorted_ary = a_to_c.sort
# 行を改行で連結、行の要素を半角スペースで連結にして末尾に改行を追加
sorted_ary.map { |item| item.join(" ") }.join("\n") << "\n"
end
puts solve(STDIN.read)
他の解答例
def solve(input_lines)
# 標準入力の受け取り
input_lines = input_lines.split("\n")
p, q, r = input_lines.shift.split.map(&:to_i)
a_to_b = input_lines.shift(p).map { |line| line.split.map(&:to_i) }.to_h
b_to_c = input_lines.shift(q).map { |line| line.split.map(&:to_i) }.to_h
# AグループとCグループの繋がりを調べる(to_h はなくてもOK)
a_to_c = a_to_b.map { |key, val| [key, b_to_c[val]] }.to_h
# a_to_c をAグループの番号順でソートして形式を整えて出力する
a_to_c.sort.map { |item| item.join(" ") }.join("\n") << "\n"
end
puts solve(STDIN.read)
今回のまとめ
今回はハッシュの基本操作の生成、データの更新、ソートを覚えました。
項目(キー)と値がセットになっているようなタイプのデータはハッシュを使うと簡単に扱うことが出来ます。

ハッシュは、最初は少し戸惑うかもしれませんが慣れるとめっちゃ便利ですよ!



