
こんにちは!じゃいごテックのあつしです。
今回はmap(map!)メソッドと、標準入力の一括読み込みを紹介したいと思います。
map・map! メソッド
繰り返しオブジェクト.map { | item | itemに対する処理 }
map
配列・ハッシュ・範囲などの繰り返しオブジェクトの各要素に対して、ブロックを評価した結果の配列を返します。
map!
配列・範囲などの繰り返しオブジェクトの各要素に対して、ブロックを評価した結果で元の変数を上書きします。(ハッシュには使えません)
例えば[1, 2, 3, 4, 5] という配列があり、各要素を2倍した配列を作りたい場合は次のように記述します。
ary = [1, 2, 3, 4, 5]
new_ary = ary.map { | num | num * 2 }
p ary
# > [1, 2, 3, 4, 5]
p new_ary
# > [2, 4, 6, 8, 10]
map!を使うとオブジェクト自身を書き換えます。このようなメソッドを破壊的メソッドと言います。
ary = [1, 2, 3, 4, 5]
ary.map! {| num | num * 2 }
p ary
# > [2, 4, 6, 8, 10]
ブロック内でメソッドを使いたい場合は下記のように記述します。
ary = ["1", "2", "3", "4", "5"]
# こう書いても動くけど
new_ary1 = ary.map { | num | num.to_i }
# このように短く書ける
new_ary2 = ary.map(&:to_i)
p ary
# > ["1", "2", "3", "4", "5"]
p new.ary1
# > [1, 2, 3, 4, 5]
p new.ary2
# > [1, 2, 3, 4, 5]
mapを使うことで、二次元配列のデータ受け取りを簡単に記述することが出来ます。
mapの使用例
1行目で半角スペース区切りの 高さh, 幅w が与えられ、続くh行に半角区切りw個のデータがある場合(二次元配列)
| 標準入力 |
| 3 4 |
| 1 2 3 4 |
| 5 6 7 8 |
| 9 10 11 12 |
h, w = gets.split.map(&:to_i) input_ary = [] h.times do input_ary.push(gets.split.map(&:to_i)) end p input_ary # > [[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]]
mapを入れ子(ネスト)にして書くと、こんな感じ。
h, w = gets.split.map(&:to_i) input_ary = h.times.map do gets.split.map(&:to_i) end p input_ary # > [[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]]
これで標準入力の受け取りは完璧!
なのですが・・・
実際に問題に挑戦してみると、動作確認で何度もキーボードで入力データを打ち込むのが面倒になってきます。
もう一工夫して、楽に確認出来るようにしてみましょう。
getsで取得できるデータの再確認
getsメソッドを使ってキーボードから"taro"と打ち込み、エンターキーで確定するとどんなデータが取得できたでしょうか?
input_str gets p input_str # > "taro\n"
では、"taro"、"jiro"、"hanako"の3行分データがあった場合は・・・
input_str = "" 3.times do input_str << gets end p input_str # > "taro\njiro\nhanako\n"
こうなります。
と言うことは、適当な変数に "taro\njiro\nhanako\n" を代入して準備しておけば、キーボードから入力する必要がなくなるのでは?
というわけで、次にヒアドキュメントのお話になります。
ヒアドキュメント
ヒアドキュメントを使うと、改行を含んだ文字列を表現することが出来ます。
さっきの例で "taro\njiro\nhanako\n" という文字列がありましたが、ヒアドキュメントを使うと次のように表現出来ます。
"EOS" の部分は最初と最後を揃えれば他の文字でも構いません。よく使われるのは "EOS", "EOL", "TEXT" です。
input_str = <<"EOS" taro jiro hanako EOS p input_str # > "taro\njiro\nhanako\n"
VSCodeなどでオートインデントが有効となっている環境だと下記のように自動修正されてしまい、無駄なスペースが入ってしまいます。
input_str = <<"EOS" taro jiro hanako EOS p input_str # > " taro\n jiro\n hanako\n"
オートインデントを有効にしている場合は、下記のように << と "EOS" の間に ~ (チルダ)を追加すればインデントを無視してくれます。
input_str = <<~"EOS" taro jiro hanako EOS p input_str # > "taro\njiro\nhanako\n"
これで入力データを毎回キーボードから打ち込まなくても良くなりました。
しかし、別の問題が発生してしまいました。
getsメソッドは、プログラミングの処理を中断してキーボードからの1行ごとの入力を行うメソッドなので、ヒアドキュメントを使う方法だと処理が止まってしまいます。
そこで、入力データを一括で読み込み出来る STDIN.read 又は STDIN.readlines の出番です。 これらのメソッドを使うと、入力開始から入力終了(EOF)までの文字列を一括で読み込むことが出来ます。
※ irbで試してみる場合、入力終了(EOF) は ctrl+D ( 環境によっては ctrl+Z ) を入力してください。
- STDIN.read
EOF までの全てのデータを読み込んで、その文字列を返します。 - STDIN.readlines
EOF までの全てのデータを読み込んで、その各行を要素としてもつ配列を返します。
今回は STDIN.read で説明します。
下記の二つのプログラムは、同じデータが input_str に入ります。
input_str = <<~"EOS" taro jiro hanako EOS p input_str # > "taro\njiro\nhanako\n"
input_str = STDIN.read # 以下、キーボードから入力 # "taro" エンターキー # "jiro" エンターキー # "hanako" エンターキー # ctrl + D p input_str # > "taro\njiro\nhanako\n"
ですので、標準入力の受け取り部分をヒアドキュメントで書いておいて、デバッグ中は STDIN.read の方をコメントアウト、提出時にはヒアドキュメントをコメントアウトすればOKです。
また、変数で色々な入力データのパターンを作っておけば、簡単に切り替えてテスト出来ますので、デバッグの効率も良くなります。
paizaの練習問題を解いてみる
N個のデータの入力 (paizaランク D 相当)
※ paiza 標準入力サンプル問題セット より
問題:
標準入力でN個の文字列が1行で与えられるので、それらを入力して、順にそのままN行で出力してください。
入力される値
1行目でNが与えらます。
2行目でN個の文字列が半角スペース区切りで与えれます。
期待する出力
N行での出力
条件
すべてのテストケースにおいて、以下の条件をみたします。
- 1 <= N <= 10
- 入力される各文字列は1文字以上100文字以下の文字列
- 入力される各文字列の各文字は英小文字または大文字または数字
入力例1
3
aaaaa bbbbbb cccc
出力例1
aaaaa
bbbbbb
cccc
入力例2
1
abc
出力例2
abc
入力例3
5
3 1 4 1 5
出力例3
3
1
4
1
5
入力例4
10
31415926 qqqqqq abab313 xyz31131 5 6 7 8 9 10
出力例4
31415926
qqqqqq
abab313
xyz31131
5
6
7
8
9
10
解答例:
入力例と出力例が4種類提示されているので、ひとまずそれをコピーして、ヒアドキュメントで変数に代入してみます。ついでに入力データの中身も確認しておきましょう。
input1 =<<~"EOS" 3 aaaaa bbbbbb cccc EOS output1 =<<~"EOS" aaaaa bbbbbb cccc EOS input2 =<<~"EOS" 1 abc EOS output2 =<<~"EOS" abc EOS input3 =<<~"EOS" 5 3 1 4 1 5 EOS output3 =<<~"EOS" 3 1 4 1 5 EOS input4 =<<~"EOS" 10 31415926 qqqqqq abab313 xyz31131 5 6 7 8 9 10 EOS output4 =<<~"EOS" 31415926 qqqqqq abab313 xyz31131 5 6 7 8 9 10 EOS p input1 # > "3\naaaaa bbbbbb cccc\n" p input2 # > "1\nabc\n" p input3 # > "5\n3 1 4 1 5\n" p input4 # > "10\n31415926 qqqqqq abab313 xyz31131 5 6 7 8 9 10\n"
ちゃんと入力データを受け取れていれば、次に処理の部分を書きます。
# 行ごとの配列を作る。
lines = input1.split("\n")
# この行はなくてもよい
n = lines[0].to_i
str_ary = lines[1].split
puts str_ary
これで完成!
input1からinput4まで試して出力結果が正しいかを確認し、問題なければ STDIN.read を使った提出用のコードに変更して提出!
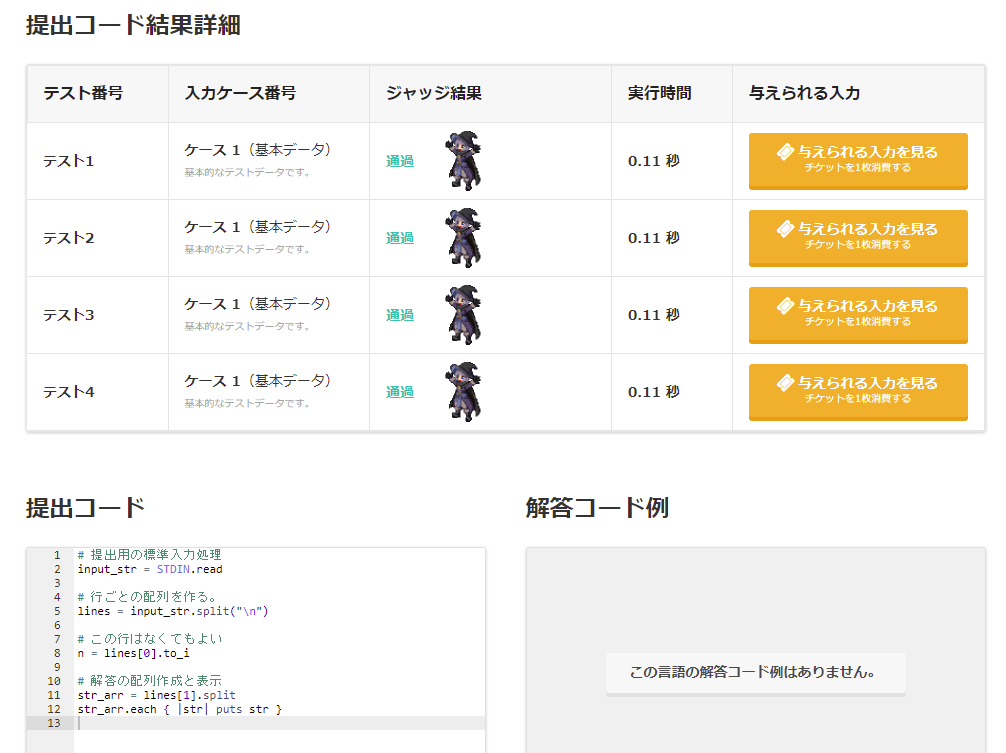
完成したコード
# 提出用の標準入力処理
input_str = STDIN.read
# 行ごとの配列を作る。
lines = input_str.split("\n")
# この行はなくてもよい
n = lines[0].to_i
# 解答の配列作成と表示
str_ary = lines[1].split
puts str_ary
今回のまとめ
- ヒアドキュメントを使って複数行の入力データを変数に格納することが出来るのでデバッグが楽
- STDIN.readやSTDIN.readlines を使うことでデータの一括読み込みが出来る
STDIN.read や STDIN.readlines を使うことによって、キーボードでのデータ入力から解放されます。
あとは多重代入を覚えれば標準入力は完璧かな?多重代入について、また今度紹介したいと思います。



